Chapter 6: Experiments
Doubt the conventional wisdom unless you can verify it with reason and experiment
— Steve Albini[1]
Learning Objectives
After reading this chapter, students should be able to do the following:
- Describe the rationale underlying an experimental method.
- Identify the criteria needed to establish causality and explain which features of an experiment support the testing of cause–effect relationships.
- Differentiate between basic and classic experimental designs; explain how exposure to the independent variable differs in between-subjects versus within-subjects designs; and explain why some designs are classified as quasi-experimental.
- Define internal and external validity.
- Identify and describe potential threats to internal validity.
- Identify and describe potential threats to external validity.
INTRODUCTION
In chapter 4, you learned that a research design is a template for a study detailing who, what, where, when, why, and how an investigation will take place. In addition to distinguishing between designs based on “when” a study takes place, as in a cross-sectional study at one point in time versus a longitudinal design conducted at multiple points in time, researchers in the social sciences sometimes classify designs as “experimental” or “non-experimental” based on their ability to determine causality. Also recall from chapter 1 how explanatory research is conducted with the aim of answering the question of “why” something occurs the way it does or to clarify why there is variation between groups on some dimension of interest. Experimental methods provide a means for testing causal relationships through the manipulation and measurement of variables. In an experiment, at least one independent variable is manipulated by a researcher to measure its effects (if any) on a dependent variable. For example, a researcher interested in the effects of sleep deprivation on scholastic performance might manipulate the amount of sleep obtained by participants. Half of the participants in the experiment might be allowed only three hours of sleep. In other words, half of the participants experience the treatment (independent variable), which in this example is sleep deprivation. The other half might be allowed to experience a normal night’s sleep of about eight to nine hours, with no sleep deprivation. The independent variable is the presumed cause of some outcome. In this example, the researcher might hypothesize that sleep deprivation will lower academic performance on a memory-based word task. In this case, participants who experience sleep deprivation should remember fewer words than participants with normal amounts of sleep, since sleep deprivation is believed to cause impaired performance. The measured performance on the memory task is the dependent variable, or the outcome.
Research on the Net
Participating in Human Research and Clinical Trials
The U.S. Department of Health and Human Services has a site full of resources to help protect the well-being of humans who volunteer as participants in health-related research (Office of Human Research Protections, 2022). Here you can find informational videos to learn more about participating in research, questions to ask researchers as a prospective volunteer, and what kind of regulations in place to protect volunteers.
CAUSALITY, CONTROL, AND RANDOM ASSIGNMENT
The study of cause–effect relationships rests on the assumption that one variable of interest is the cause of another; that is, changes in one variable produce changes in another. To establish a causal relationship, three criteria must exist. First, the variables must be related in a logical way. For example, education and income are associated, as people with higher levels of education also tend to earn more. This is sometimes referred to as the “covariance rule” (Beins, 2018, p. 163). Second, the cause must precede the effect in time, establishing “temporal order.” A person acquires an education and then enters the workforce to earn an income. Finally, the presumed cause should be the most plausible one and rival explanations should be ruled out. Although education contributes to income, there are other factors that help to explain one’s income, including age, years of experience, family socioeconomic status (i.e., how well off a person’s family of origin is), and type of employment. These factors cannot be completely ruled out from this example. While we have established an association, we have yet to prove causation. This can only be done by conducting an experiment.
Experimental methods common to the natural sciences are also regularly employed by psychologists and used to a lesser extent by sociologists, such as social psychologists and criminologists. Although experiments often conjure up images of scientists wearing white lab coats working with beakers in research laboratories, they can be conducted anywhere a researcher has control over the environment. Just as an instructor can close a classroom door and lock it, thereby preventing people from entering the room during a lecture, a researcher can follow standardized procedures, use scripts, and take precautions to turn a classroom, office, and/or some other area on campus into a carefully controlled laboratory setting.
Experiments constitute the only method that can demonstrate causation due to the strict environmental control and the random assignment of cases to the treatment. Random assignment is a method for assigning cases to the experimental group (the one that receives the independent variable) based on chance alone. This is important because, going back to the original example on sleep deprivation, some individuals require more sleep than others, some have better working memories than others, and some have higher overall scholastic aptitude than others—all of which can influence performance on the word task, as can mood, time of the day, and whether the person has recently eaten. If participants are randomly assigned to a sleep deprivation group or a normal sleep group, then any existing individual differences will also be randomly assigned across the groups, making them equivalent at the onset. The group exposed to the independent variable is called the experimental group and the group that does not experience the independent variable is called a control group. The control group provides a measure of what would “normally” happen in the absence of the experimental manipulation. In the example used earlier, the control group tells us how many words on average people can recall during a word task. We can then compare the results for the sleep-deprived experimental group to the results for the control group to see if the experimental group fares worse, as hypothesized.
Therefore, with random assignment and strict control over the environment, where both groups receive identical instructions and undergo the exact same experience except for the independent variable, we can be reasonably sure that any differences found between the two groups on some measure result solely from the manipulation. Using the previous example, if the sleep-deprived group performs worse on the word task, we can attribute the difference to the independent variable.
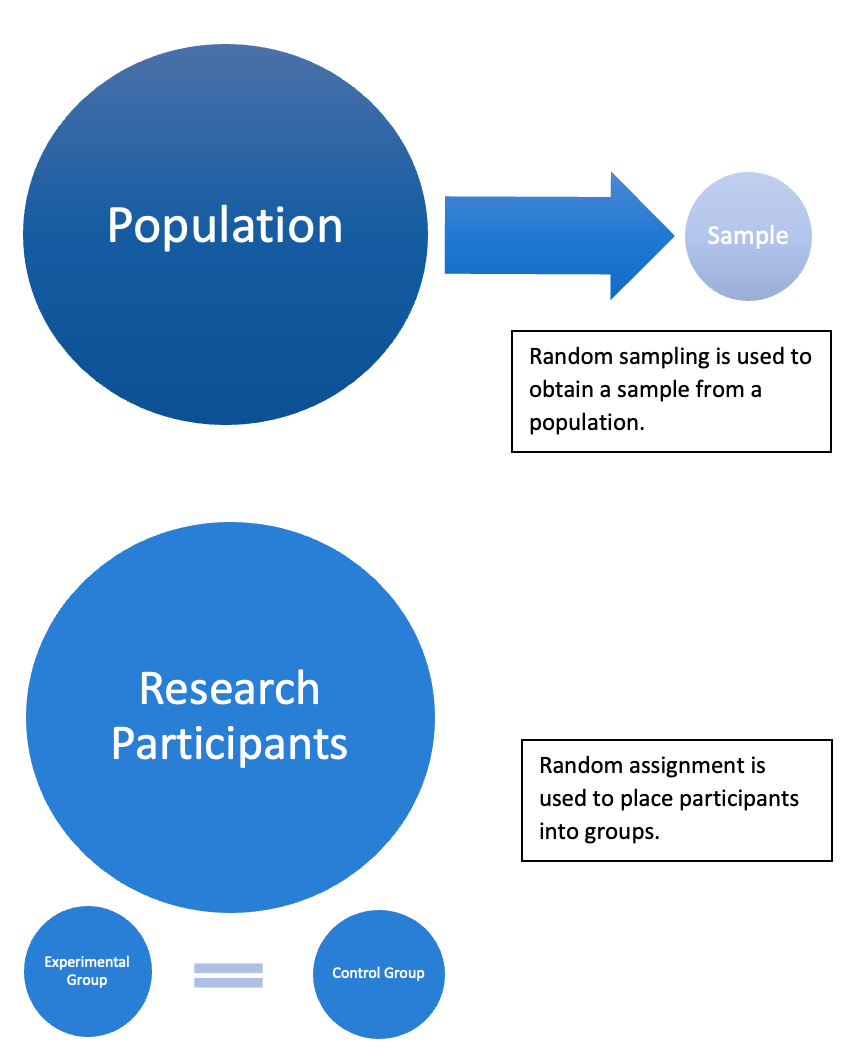
Students routinely confuse random sampling (discussed in chapter 5) with random assignment. Try to remember that random sampling has to do with how a sample is selected from a population of interest. This process permits a researcher to generalize from the sample to the population. For example, one of the probability-based sampling methods is simple random sampling, where a sample of a given size is obtained using a random-numbers generator. This means chance alone determines who is selected to take part in a study. Random assignment, on the other hand, has to do with how participants are put into groups in experimental research. In this case, chance alone determines who from the collection of sample subjects ends up receiving the manipulation (see figure 6.1). Random assignment helps ensure the experimental and control groups are identical before the experimental manipulation.
Since the hallmark of an experiment is the manipulation of an independent variable presumed to be the cause of a change in the dependent variable, researchers often incorporate a “manipulation check” into their study procedures to be certain the experimental group experienced the independent variable as intended. For example, participants might be asked to report on how much sleep they received. Those in the experimental group should say they received about 3.0 hours sleep, while those in the control condition should indicate about 8.5 hours, on average. Similarly, an experimenter studying the effects of watching a video on subsequent attitudes might ask participants a question or two about the video to gauge whether they watched it. This is an important check to see that the procedures of the experiment unfolded as intended.
Activity: Components of Experimental Research
Test Yourself
- Which variable is manipulated in an experiment?
- What three criteria must exist to establish a causal relationship?
- How can random assignment be distinguished from random sampling?
TYPES OF EXPERIMENTAL DESIGNS
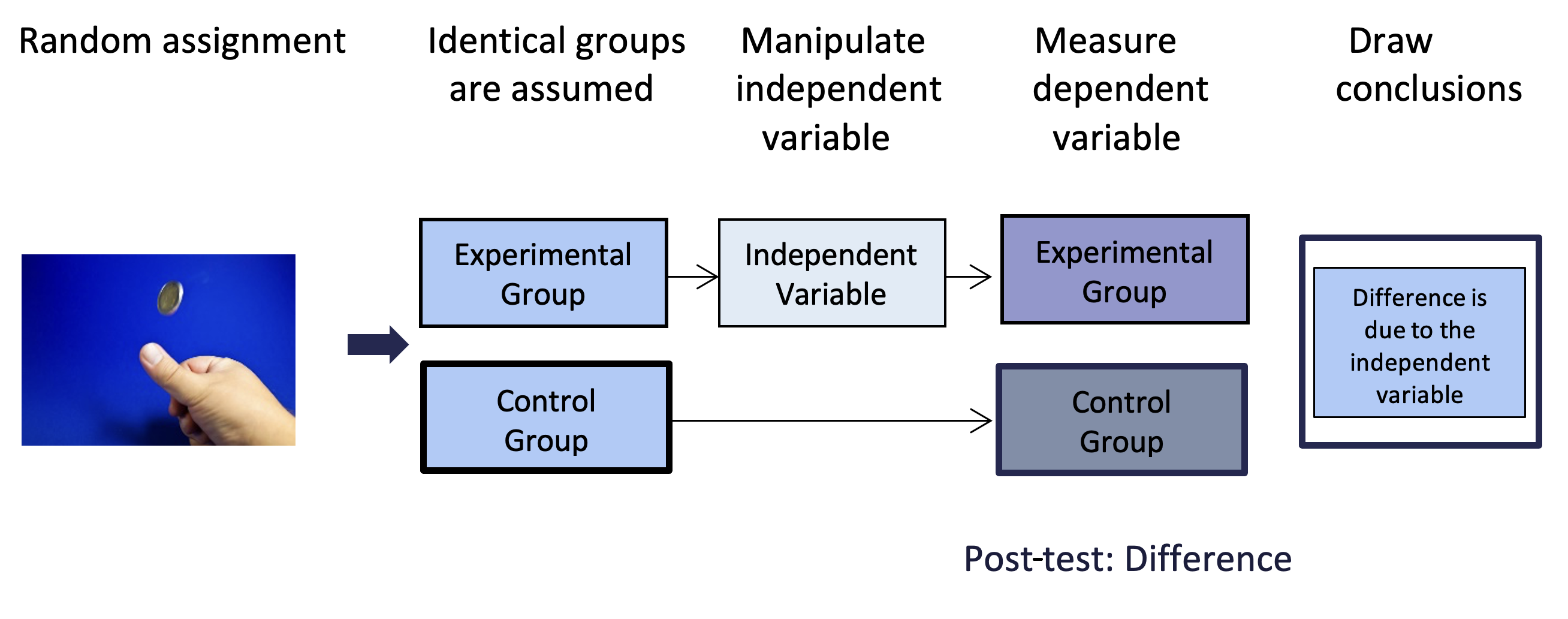
There are many different types of experimental designs. What makes any experiment a “true” experiment is the presence of four core features: (1) random assignment, (2) an experimental and a control group, (3) the manipulation of an independent variable experienced by the experimental group, and (4) the measurement of a dependent variable (i.e., the outcome) to see what (if any) effect the independent variable had. This is usually referred to as a “post-test.” An experimental design that includes these four features and only these four features is referred to as a basic experimental design (see figure 6.2).
Classic Experimental Design
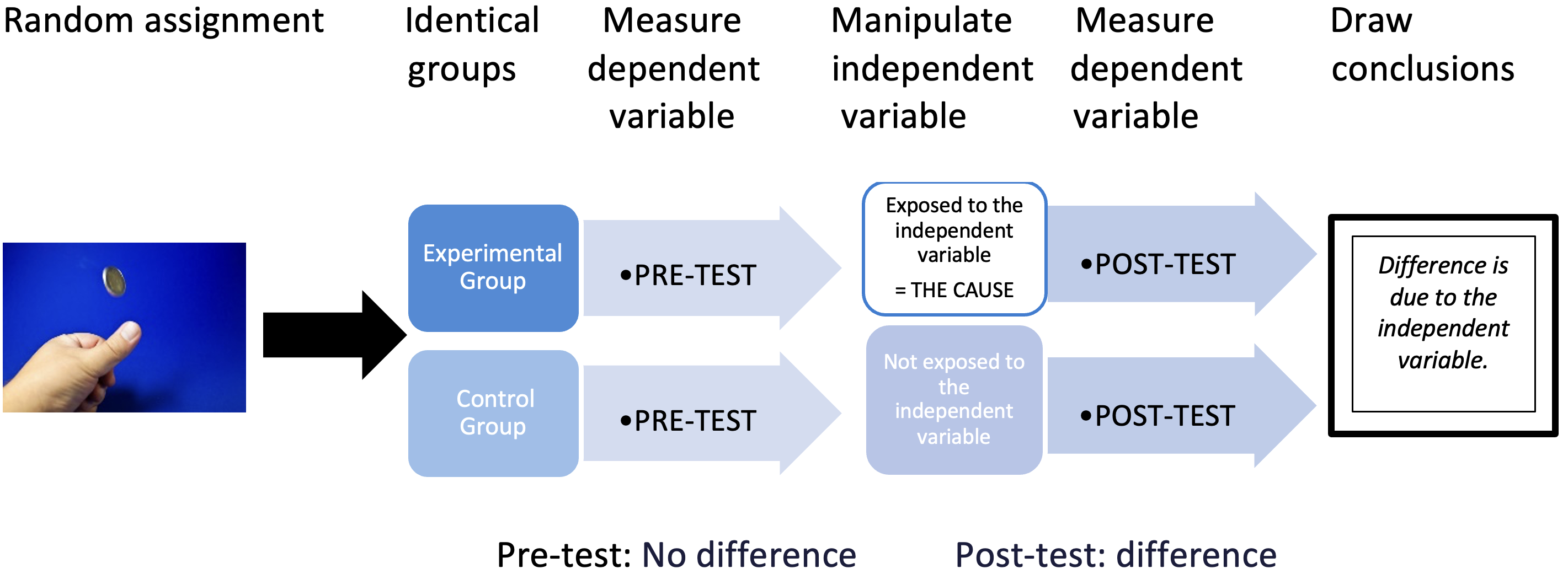
A classic experimental design includes the four basic features from the basic design (random assignment, an experimental and a control group, the manipulation of an independent variable, and a post-test measurement of the dependent variable), along with a pre-test of the dependent measure. This design is also commonly called a pre-test–post-test design. Even when random assignment is used to place participants into groups, there may be differences between the groups starting out. For example, perhaps some of the participants who end up in the experimental group have exceptional memories or are great at word tasks. If a basic experimental design is used, then the dependent variable is measured only once following exposure to the independent variable, during the post-test. Due to the exceptional qualities of the participants in the experimental group, the researcher might find no differences in word recall between the experimental and control groups. It appears that the independent variable, sleep deprivation, had no impairing effect on performance. But what if the experimental group had done even better had they not been sleep deprived? With only one measure of the dependent variable, an experimenter will never know the answer. However, if performance is measured before and after exposure to the independent variable, we can see how much performance is impaired by sleep deprivation. In a classic experimental design, participants are randomly assigned to an experimental or control group and then given a pre-test, where the dependent variable is measured prior to exposure to the manipulation (i.e., the independent variable). The participants in the experimental group then receive the manipulation (i.e., are sleep deprived), and both groups are reassessed (i.e., given a post-test) on the dependent variable, as outlined in figure 6.3.
Between-Subjects and Within-Subjects Designs
In the designs discussed thus far, the experimental group is exposed to an independent variable and the control group is not. The experimental group can experience an independent variable in two ways: It can be assigned either to one or all levels of the independent variable. In a between-subjects design, participants in the experimental group are exposed to only one level of the independent variable. For example, in an experiment on the effects of music on personality, undergraduates at a Canadian university were randomly assigned to one of three possible conditions where they (1) listened to a classical song while reading the English translation of the lyrics, (2) listened to a classical song and followed along with the text provided in German, or (3) listened to an English translation of the lyrics (Djikic, 2011). This is called a between-subjects design because there are differences between participants (also known as subjects) in how they experience the independent variable. This type of design is also called an “independent groups design” since each fraction of the experimental group independently receives one treatment. One-third of the participants heard the song while reading the English translation (a music and lyrics condition), one-third listened to the song while looking at German lyrics (described as a music only condition since no one in the study understood German), and one-third listened to the English translation (lyrics only without the music). In case you are curious, Djikic (2011) found that listening to classical music changed the participants’ personalities for the better, leading to a self-reported enhanced variability in overall personality, while exposure to lyrics but no actual music produced a diminished variability in personality.
In a within-subjects design, the participants in the experimental group are exposed to all levels of the independent variable. For example, in an experiment on participants’ willingness to endure a painful exercise for money, Cabanac (1986) paid 10 participants varying amounts of money to endure an isometric sitting exercise. Isometric sitting is akin to sitting without a chair, with one’s legs at a 90-degree angle, causing lactic acid to build up in the thigh muscles to produce a painful sensation. Using a within-subjects design, all participants were exposed to the six different levels of the independent variable, wherein they were paid 0.2, 0.5, 1.25, 3.125, or 7.8125 French francs (FF) per 20 seconds of exercise or a lump sum, presented in a random order. For example, participant number one attended their first session and might receive 0.2 FF for every 20 seconds of exercise during that session, 1.25 FF at the next session, 7.8125 FF at the third session, 3.125 FF at the fourth session, a lump sum on the fifth session, and 0.5 FF at their last session. All participants experienced the same conditions; however, the order of presentation differed (e.g., participant number two might receive the lump sum during their first session and the highest pay amount during their second). In this case, the difference in how the independent variable occurs is within the participants themselves, who each receive the treatments in random order. Cabanac (1986) found that money motivated participants’ willingness to endure pain up to a certain point: participants lasted longer for increasing amounts of money, but eventually they were unable to continue the exercise due to physical limitations beyond their desire to continue to withstand the pain for money.
A within-subjects design is also called a repeated measures design since participants are exposed to the independent variable repeatedly at multiple points in time. In a within-subjects/repeated measures design, participants may receive exposure to the same condition repeatedly as opposed to encountering different levels of the independent variable at different times. For example, McConville and Virk (2012) used a repeated measures design to examine the effectiveness of game-playing training using the Sony PlayStation 2 and EyeToy combination with the Harmonix AntiGrav game for improving postural balance. Participants were randomly assigned to either the control group (no training) or the experimental group (attended nine scheduled training sessions over a period of three weeks). During each 30-minute training session, the participants played the game four times using the controls and incorporating necessary head, body, and arm movements. Participants who underwent game training showed significant improvement on two different facets of balance (McConville & Virk, 2012).
One potential drawback of this type of design is its tendency to create order effects. Order effects are differences in the dependent variable that result from the order in which the independent variable is presented (as opposed to the manipulation itself). For example, imagine you are interested in learning whether people state a preference for a brand of cola (e.g., Pepsi or Coke) in a blind taste test. If, as the researcher, you always gave participants Coke first, it could be that the initial brand tasted lingered in a participant’s mouth, confounding or interfering with the taste of the next cola; that is, effects from trial number 1 have carried over into trial number 2. To control for this, the researcher could increase the time between trials 1 and 2 (to ensure the taste of the first cola has dissipated) or the experimenter could offer water in between trials to eliminate the traces left from trial 1. Alternatively, the researcher could employ a technique called “counterbalancing,” where all possible ways to order the independent variable are included in the design. For example, on half of the trials Coke would be presented first, and on half of the trials Pepsi would be presented first.

Quasi-Experimental Designs
Although you might be inclined to infer that a more complicated design is always a better one, there are many instances in which even a basic experimental design cannot be used.
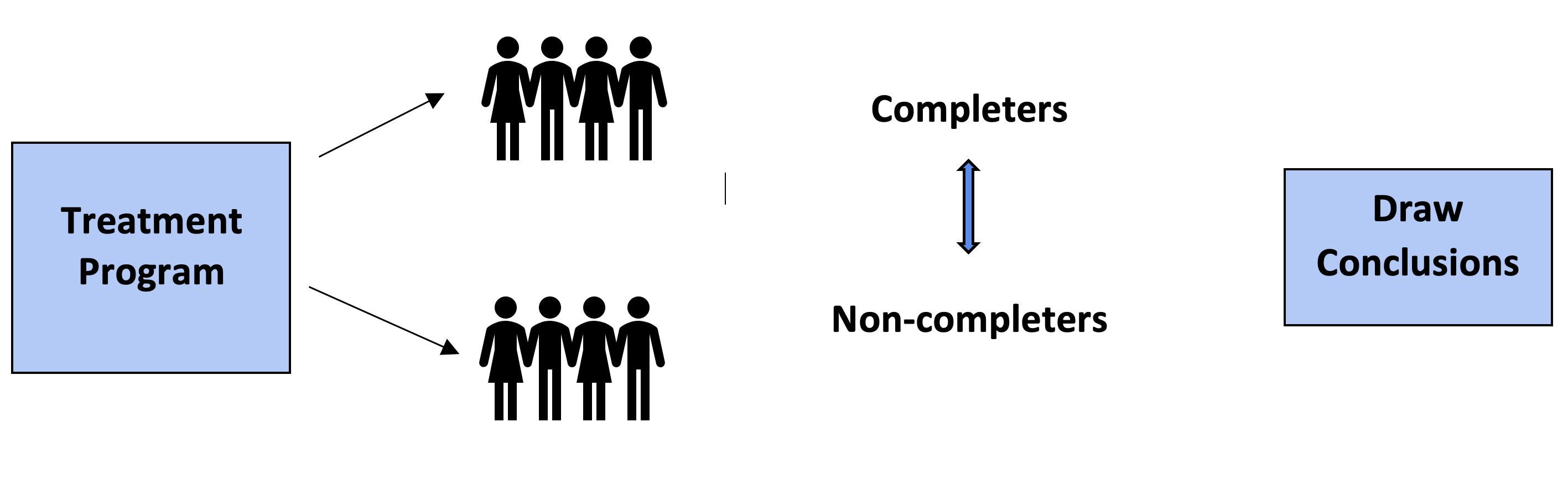
For instance, a counsellor who works with clients in a Manitoba-based treatment program for adolescents, such as the Edgewood Program (for male youth who have committed a sexual offence) or the Mutchmor Program (for adolescent males with aggressive tendencies), might be interested in examining the effects of program completion on reoffending. It would be unethical and potentially unsafe to randomly offer treatment to certain offenders and not others to see if the treated group is less likely than the untreated group to reoffend at some point in the future. However, some offenders voluntarily enter treatment programs, while others do not. And, similarly, some offenders who enter treatment programs complete treatment, while others fail to complete the full course of the treatment (e.g., they fail to comply with the rules and are asked to leave the program or they decide to quit the program). While random assignment to the independent variable (treatment) is not possible, naturally occurring groups sometimes become available for studying, such as treatment completers and non-completers. These groups might be compared to see if those who complete treatment have lower reoffending rates (the dependent variable) than those who fail to complete the treatment program.
Experimental designs lacking in one or more of the main features of a true experiment are commonly referred to as quasi-experimental designs (also called pre-experimental designs). Quasi-experimental designs are especially prevalent in research projects designed to examine the effectiveness of treatment programs in areas such as clinical psychology, sociology, and social work. One of the most common types of quasi-experimental designs is a static group comparison, where there are two groups and a post-test measure, but random assignment was not an option for the placement of participants into the two groups. Instead, participants typically end up in the two groups as a function of self-selection. For example, a static group comparison might be used to examine treatment completers versus non-completers in a rehabilitative program for sexual offenders (see figure 6.4). Allowing time for reoffending to occur following treatment (e.g., a period of up to five years), the research question of interest, then, could be “Is reoffending (called recidivism) lower in treatment completers compared to non-completers?” A static group comparison is also useful for examining the differences between groups in situations wherein one group receives a novel treatment or when one group receives a placebo (or simulated treatment) while the other does not (Thyer, 2012). In evaluating the merit of a static group comparison, it is important to note that this design is often used in research that is more of a starting place for determining if a program or intervention appears to be effective. While static group comparisons are frequently employed to compare groups to see if a treatment helps, without random assignment, causal inferences are difficult to establish. For example, there could be important differences between offenders who complete treatment and those who do not, which account for the lower recidivism, irrespective of what went on in a given treatment program.
Another common quasi-experimental design is a one-shot case study, where a group receives exposure to an independent variable and then is measured on a dependent variable. This design lacks a control group (see figure 6.5). One-shot case studies are commonly employed in social work and educational research. In his book on quasi-experimental designs, Bruce Thyer (2012) notes that one-shot case studies play an especially important role in answering questions concerning the effectiveness of various interventions and programs such as “What is the status of clients after they have received a given course of treatment?” and “Do clients improve after receiving a given course of treatment?”

Research in Action
Impression Formation
In a classic study on impression formation, Solomon Asch (1946) read a list of peripheral character traits used to describe someone’s general disposition—intelligent, skillful, practical, etc.—to a group of participants and then had participants describe the sort of person to whom the traits might apply. All participants heard the same list read except for one word. Half of the participants heard the word warm, while the other half heard the word cold included among the descriptors. Results showed that participants exposed to the word warm created much more favourable impressions than those who were exposed to the word cold. Asch (1946) explained that only certain words (such as warm and cold) are “central traits” that have an overall effect on impression formation, as demonstrated in his early study. In this example, only an experimental group was exposed to the independent variable (the warm or cold descriptor) and then measured on the dependent variable (i.e., their impression). This allowed the researcher to examine for an overall main effect, the difference between the warm and cold condition. However, without a control group, it was not possible to say which condition accounts for the effect. It could be that the warm descriptor produced a favourable impression and this alone accounted for the difference between the warm and cold condition, with the cold perhaps not having any effect. Conversely, it could be that the cold descriptor negatively impacted the impression to create the difference between the cold and warm condition, and the warm condition on its own perhaps did not have any impact. Finally, it could be that both the warm and cold descriptors produced separate main effects.
Test Yourself
- What four features underlie a true experimental design?
- What main feature distinguishes a classic experimental design from a basic design?
- Which type of quasi-experimental design lacks a control group?
INTERNAL AND EXTERNAL VALIDITY
Recall how validity is an important consideration in evaluating whether a study is properly measuring/assessing the central concepts and constructs of interest. In other words, is a study properly examining what it is supposed to? In an experiment, validity takes on an even greater level of importance as a researcher tries to prove causation and generalize the findings beyond the confines of that study. Internal validity refers to the capacity to demonstrate an experimental effect and to rule out rival explanations for that effect. Campbell and Stanley (1963) coined the term internal validity, referring to it as “the basic minimum without which any experiment is uninterpretable: Did in fact the experimental treatments make a difference in this specific experimental instance?” (p. 5). In other words, internal validity pertains to whether a causal relationship has been established. A study has high internal validity if a researcher can demonstrate that it is highly likely an independent variable produced the outcome (i.e., the differences between groups observed on the dependent variable were due solely due to the independent variable) and it is highly unlikely that alternative explanations can account for the effect. Random assignment to an experimental and a control group helps to establish internal validity by minimizing differences between the groups prior to the experimental manipulation.
External validity refers to the generalizability of the effect or outcome beyond an experiment. In other words, do the results generalize to other people in other settings at other times? Does sleep deprivation impair performance in general, such as other cognitive or behavioural areas of functioning in the real world for most people, or is it limited to the results found in this study measuring performance on a word task with these participants? Random sampling helps to establish external validity because it eliminates bias generalizing from the sample to the population (Dorsten & Hotchkiss, 2005).
Internal and external validity are related in a manner that is considered a trade-off in experimental research. With high internal validity, a researcher can be sure the independent variable is the cause of any differences found between the experimental and control group on the dependent measure. However, the greater the control over the environment, which is high for most laboratory experiments, the more artificial and less lifelike the study becomes and the less likely the experiment will generalize to the real world (external validity). This can be countered by using a field experiment, where the experiment occurs naturally in a real-life context. For example, the Smithsonian Tropical Research Institute conducts field experiments in different locations on the effects of global climate change on tropical plants, such as by looking at plant responses to various levels of carbon dioxide concentrations. Similarly, social researchers examine variations in the behaviour of groups that take place in actual social situations, such as performance on a sports team, shopping behaviour in a supermarket, motorist responses at busy intersections, and student engagement in a classroom. Although field experiments have higher generalizability because they take place in the real world, there is very little control over that environment, and the isolation of variables can be quite problematic. As a result, high external validity corresponds to low internal validity and vice versa.
Test Yourself
- What is the term for the generalizability of an experimental effect?
- How are internal and external validity related?
THREATS TO INTERNAL VALIDITY
In their pioneering work on experimental design, Donald Campbell and Julian Stanley (1963) identify eight considerations they refer to as “classes of extraneous variables” that need to be carefully controlled for within an experimental design or ruled out as possibilities via careful consideration. Otherwise, these unintentional variables can confound or interfere with the effects of the independent variable and make it difficult to properly assess the findings. The eight classes of extraneous variables are now more commonly recognized as “threats to internal validity” and they include selection, history, maturation, selection by maturation interactions, experimental mortality, testing, instrumentation, and statistical regression.
Selection
As a threat to internal validity, selection refers to methods used to obtain groups that can result in differences prior to the experimental manipulation. Recall how true experimental designs rely upon random assignment to achieve identical groups at the onset of the study. The first threat to validity concerns any practices that can lead to a selection bias, where the two groups are not identical at the beginning of the study. For example, allowing participants to self-select into groups can produce differences between the experimental and control groups since certain individuals opted for the treatment, while others chose to avoid it (Mitchell & Jolley, 1996). Using my earlier example, if participants who normally need a lot of sleep opt to be in the control condition because they would prefer to avoid sleep deprivation and those who end up in the sleep deprivation treatment choose it because they do not feel they require the normal amount of sleep, the effects of the independent variable may be nullified. This is because those least impacted by sleep deprivation self-selected themselves into the study, while those likely to be most impacted opted out. A similar problem would occur if a researcher purposely assigned participants to the groups in a manner that appeared arbitrary but was in fact not, as would be the case if a teacher assigned students in the front of the class to one group and the back of the class to another (Mitchell & Jolley, 1996). To help assess whether selection is a threat to internal validity in a given study, ask yourself, “Can I be sure the experimental and control groups are identical at the onset of the study?” This threat can be prevented using random assignment.
History
Another potential threat to internal validity concerns what is called history, which refers to changes in the dependent measure that are attributed to external events other than the independent variable and that occurred between the first and second measurement. This threat pertains to classic experimental designs or other designs containing a pre-test and post-test measurement of the dependent variable. For example, suppose a researcher is interested in the effects of exposure to information on government cutbacks on students’ attitudes toward tuition hikes. If large-scale student tuition protests take place during the testing periods, it is unclear whether changes in students’ attitudes toward tuition from time one to time two result from learning about government cutbacks (the experimental manipulation) or the coinciding historical event. To help assess whether history is a threat to internal validity in a given study, ask yourself, “Is it possible that some other event outside of the study produced these findings?” This threat cannot be avoided, but random assignment will help ensure that both groups experience its effects similarly. In addition, the inclusion of a pre-test will indicate if a history effect may have occurred, since there will be a difference between the pre-test and post-test for both groups, even the control group that did not experience the independent variable. Note that the difference will only indicate that history is a potential problem. The difference could also be the result of maturation, as discussed next.

Maturation
A third potential threat to internal validity pertaining to experimental designs containing a pre-test and post-test is maturation. In the context of experimental research, maturation refers to changes in the dependent measure that result from processes within the research participants themselves over the period of treatment, such as growing older, gaining experience, or growing fatigued. For example, Palys and Atchison (2014) provide a simplistic case of a researcher interested in whether the administration of pills will help children learn to walk. If the participants are one-year-olds and none of them are walking at Time 1 but all of them are walking at Time 2, it is impossible to determine if the pill administered on a monthly basis for a year (as the treatment or independent variable) facilitated walking or if a natural biological process attributed to maturation resulted in all of the children walking at age two (p. 238).
Although none of the features of the designs discussed in this section protect against maturation, you can question whether this threat might be operating in studies showing a difference in the dependent measure at Time 1 and Time 2 for a control group. It cannot be the experimental manipulation that accounts for the unexpected change because this group is not exposed to the independent variable. To help assess whether maturation is a threat to internal validity in a given study, ask yourself, “Is it possible that naturally occurring changes within the participants are responsible for the findings?” Like history, this threat cannot be avoided, but random assignment will evenly distribute the effects across the experimental and control groups, and a pre-test will provide evidence of a difference that may be attributed to maturation.
Selection by Maturation Interaction
The influence of maturation can sometimes be driven by the initial selection of the experimental and control groups. In a selection by maturation interaction, there is a combined effect of initial differences in the groups at the onset of the study alongside maturation effects. For example, suppose a researcher assigned six-year-old boys to an experimental group and six-year-old females to a control group for a study on spatial skills. The experimenter believes that they can design an exercise program that will improve spatial skills. Both groups are measured at time 1, then the researcher spends a few months designing their program and places the boys in the exercise program where they do special drills once a week for an hour over the course of three weeks. Both groups are measured about a month after completing the program, and the boys show marked improvement in spatial skills compared to the girls. In this example, several factors could account for the findings. First, there could be differences in spatial skills between boys and girls to begin with. In addition, even if there are no initial differences between boys and girls, it could be that over a course of several months, the boys engaged in a variety of activities that the girls did not that inadvertently led to improvements in their spatial skills, irrespective of the specialized exercise program. For example, some may have participated in organized sports such as baseball or soccer, while others perhaps played sports during their recess breaks and over the lunch hour.
To help assess whether a selection by maturation interaction is a threat to internal validity in a given study, ask yourself, “Is it possible that the two groups would have eventually become different, irrespective of the independent variable?” Again, random assignment helps to improve internal validity by eliminating biases that could otherwise be present at the onset, and a pre-test for the control group helps to establish whether maturation is a possibility that could otherwise be mistaken for a treatment effect.

Experimental Mortality
A fifth potential threat to internal validity is experimental mortality, referring to the loss of participants due to a discontinuation of voluntary participation over time. Simply stated, the longer a study carries on, the greater the odds are that participants will drop out of the study for any number of reasons (e.g., they move, they lose track of the study, they lose interest). Mortality, also called attrition, is an inherent problem in longitudinal studies, particularly ones conducted over many years and ones that involve time-consuming and even unpleasant contributions from participants. For example, although highly important to our eventual understanding of the development of cancer among Canadians, Alberta’s Tomorrow Project periodically requests that participants complete detailed documents on their food intake, activity levels, and body measurements. In addition, they are asked to go to a health clinic to provide saliva samples, urine samples, and blood samples (Alberta’s Tomorrow Project, 2024c). What if the participants who are most motivated or healthiest choose to remain in the study and those who are least motivated or least healthy drop out? To help assess whether mortality is a threat to internal validity in a given study, ask yourself, “Did more participants drop out of the experimental compared to the control group (or vice versa)?” While mortality cannot be prevented by an experimental design feature, it can be reduced, where possible, by limiting the overall time frame for a study or by taking the pre-test and post-test measures at close intervals in time. By examining the pre-test and post-test measures for the control group, a researcher can see if a change in the group size has potentially influenced the results of a study. Finally, it is especially important to monitor the number of participants in each group to see if more participants drop out of one group relative to the other.

Testing
Although a pre-test is very important for indicating the presence of potential threats, such as mortality or maturation, testing itself can even pose a threat to the internal validity of an experimental design. Just as students in a class sometimes perform better on a second midterm once they have gained familiarity with how a professor designs and words the questions on exams, participants may improve from a first test to a second test, regardless of the experimental manipulation. In this case, a researcher would expect both the experimental and control group to show improvement. If the independent variable has an effect, the change should be greater for participants in the experimental condition. To help assess whether testing is a threat to internal validity in a given study, ask yourself, “Is it possible that participants’ test scores changed due to experience or familiarity gained from taking a pre-test?” The necessary feature for determining whether testing is a potential threat is the inclusion of a control group.

Instrumentation
Instrumentation refers to any changes in the way the dependent variable is measured that can lead to differences between Time 1 and Time 2. For example, a researcher might change a measuring instrument such as a scale or index because a newer or more improved version becomes available between Time 1 and Time 2. Alternatively, an observer or rater might fall ill or otherwise be unable to obtain measurements at both time periods, and there may be differences between how the first and second observer interpret events that influence the results. To help assess whether instrumentation is a threat to internal validity in a given study, ask yourself, “Were there any changes to the way the dependent variable was measured between the pre-test and post-test that might account for the findings?”
Statistical Regression
Finally, as Mitchell and Jolley (1996) point out, “even if the measuring instrument is the same for both the pre-test and post-test, the amount of chance measurement error may not be” (p. 143). Extreme scores are sometimes inflated by measurement error. That is, with increased measurement (as in testing someone at two points in time), extreme scores or outliers tend to level off to more accurately reflect the construct under investigation. In statistical terms, this is a phenomenon known as regression toward the mean. For example, researchers interested in helping people overcome phobias, obsessions, or behavioural disorders such as attention deficit might try to include participants likely to display extreme scores on a pre-test because extreme scores are indicative of those who are out of the range of normal and therefore have an actual disorder that needs to be managed. However, it is also likely that participants with extreme scores will show some improvement (their scores will go down from Time 1 to Time 2) regardless of the treatment, as they cannot really go any higher (since they are already extreme), and they are likely to have some good days and some bad days. There is a change in the dependent measure, but “the change is more illusory than real” (Palys & Atchison, 2014, p. 239). To help assess whether regression is a threat to internal validity in a given study, ask yourself, “Is it possible that participants were on the outlier or extreme end of scoring on the pre-test?” To help control for the statistical regression, a researcher can try to avoid the use of participants with extreme scores.

Test Yourself
- What is the name for the threat to internal validity that results from methods used to obtain participants that result in differences prior to the experimental manipulation?
- Which threat to internal validity results from processes occurring within the participants?
- What is the name for the threat resulting from the combined effect of initial differences in the groups at the onset of the study alongside maturation effects?
- Which threat is assessed by asking “Were there any changes to the way the dependent variable was measured between the pre- and post-test that might account for the findings?”
- What question should be asked to see if regression toward the mean is a threat to validity?
THREATS TO EXTERNAL VALIDITY
Recall that external validity pertains to the ability to generalize beyond a given experiment. While a psychologist might rely upon a convenient sample of introductory psychology students who consent to participate in their study on jury deliberations, they are relying on the findings from their research to better inform him about how most Canadian jurors deliberate during trials. Just as there are threats to internal validity, there are features of experimental designs that can jeopardize the generalizability of findings beyond the experimental settings and participants on which they were based. In this section, I discuss the three common threats to external validity: experimenter bias, participant reactivity, and unrepresentative samples.
Experimenter Bias
In an earlier chapter, you learned about sources of error in measurement and how a researcher might try to help along a study in order get a desired outcome. Experimenter bias “exists when researchers inadvertently influence the behavior of research participants in a way that favors the outcomes they anticipate” (Marczyk et al., 2005, p. 69). For example, a researcher who expects sleep deprivation to hinder performance might distract participants in the experimental condition or fail to give them the full instructions for how to complete the task, whereas those in the control condition might receive additional cues that aid performance. Although experimenter bias is one of the most common and basic threats to external validity (Kintz et al., 1965), there are ways to minimize its occurrence. First, procedural control in an experiment can include the use of scripts to ensure a researcher reads the exact same instructions to each of the participants. Alternatively, control can even be removed from the researcher such that participants might receive typed instructions, watch a video clip, or hear an audio recording that describes how to carry out the task that is being measured in the study. Anything that can be done to standardize the procedures to help ensure identical treatment for the control and experimental group (except for the independent variable) will reduce the likelihood of experimental bias.
In addition to standardized instructions and procedures, where possible, experimenters should not be allowed access to the outcome measure while it is taking place. For example, in Symbaluk et al.’s (1997) pain experiment, the dependent variable was how long participants lasted at an isometric sitting exercise. Participants ended a session by sitting down on a box that contained a pressure plate that stopped a timer. The experimenter was not in the same room with the participants while they performed the exercise and therefore could not influence how long they lasted at the exercise. Further, a recording device (not the experimenter) indicated how long each participant lasted.
Finally, in some studies it is possible to keep an experimenter or research assistant “blind” to the important features of the study until after the dependent variable is measured. For example, in the pain experiment, an assistant was in the room with the participants while they performed the exercise. The assistant recorded pain ratings at regular intervals and noted when participants ended the exercise. The assistant was never informed about the hypothesis or the independent variable, or whether any given participant was in an experimental or control condition. As a result, the assistant had no reason to create an experimenter effect. It may even be possible to utilize a “double-blind” technique, where both the researchers/assistants and the participants are unaware of which participants are assigned to the experimental and control conditions. In the pain experiment discussed above, participants were not informed about the other conditions until the completion of the study, so they could not form an expectation about whether they should or should not do well based on features of the study, such as the amount of money they were being paid relative to others. Participant bias is discussed in the next section.
Research in Action
Basic Instincts, Part 5. The Milgram Experiment Re-Visited
Recall the now classic experiments on obedience conducted by Stanley Milgram in the 1960s that were discussed in detail in chapter 3 as an example of unethical research due to the prolonged psychological harm experienced by participants who believed they were giving painful electric shocks to a learner. Professor Jerry Burger, an emeritus social psychologist from Santa Clara University, partially replicated Milgram’s studies in an experiment that was broadcast on January 3, 2007, as part of an ABC News Primetime television program, called Basic Instincts. Surprisingly, participants were almost as obedient in this study as they were in Milgram’s original versions. To learn how Burger created a “safer” version of Milgram’s procedures and to find out if there are differences in obedience between males and females, check out the video published by ABC News Productions. For more information on the video and Burger’s (2009) article summarizing this study, called “Replicating Milgram: Would People Still Obey Today?” published in American Psychologist, refer to Jerry Burger’s professional profile (archived version).
Participant Reactivity
A second source of bias rests with participants themselves. Participant reactivity refers to the tendency for research participants to act differently during a study simply because they are aware that they are participating in a research study. This sometimes occurs because participants try to “look good,” suggesting a social desirability bias, or they pick up on what the study is about and try to help the researchers prove their hypothesis by following demand characteristics, as discussed in chapter 4. One way to lessen participant reactivity is to withhold details regarding the hypothesis and/or experimental manipulation from the participants until after the dependent variable is measured. For example, suppose we were interested in whether students would help a fellow classmate get caught up on missed lecture notes. The dependent variable is whether students agree to loan their notes. Perhaps we hypothesize that students will be more willing to loan notes to someone who was sick from class versus someone who skipped class. We can manipulate the independent variable by sending one request to half of the class asking if anyone is willing to loan their notes to a fellow classmate who was recently ill, and a request to the other half of the class asking if anyone is willing to loan their notes to a student who missed class to attend a Stanley Cup playoff game. If we told the class ahead of time we were studying their willingness to help a classmate, they might react to the request in order to appear helpful, irrespective of the independent variable.
Participant effects are also sometimes controlled for with the use of deception, where participants are led to believe the experimenter is investigating something different than the true purpose of the study. In the example above, we might use a cover story in which we tell the students we are studying aspects of internet usage and have them complete a short questionnaire asking about their familiarity with and time spent on sites such as Facebook and X. As they complete the short survey, we might pass out the request for help. The request might be in the form of a handout that has a spot at the bottom where they can check off a box if they want to lend notes and leave a contact. We could then collect the handout along with the completed questionnaires.
In cases where participants are not informed about the hypothesis under investigation or they are misled about the hypothesis, at the completion of the study the investigators may ask participants if they can guess the hypothesis under investigation. A participant who accurately states the hypothesis under investigation despite the researcher’s attempts to conceal it would be considered “suspicious,” and the results for the experiment would be examined with and without suspicious cases as a further check to determine if reactivity was a problem. Deception and the withholding of information is used only rarely in experimental research—typically involving social psychological processes that would be negated by full disclosure (e.g., willingness to help) because the practice goes against the participants’ ethical rights to informed consent. In all cases where information is withheld from participants or they are deceived by a cover story or misled in any way by procedures used in the experiment, a detailed debriefing must occur as soon as possible. The debriefing should include full disclosure of the nature and the purpose of any form of deception and allow the participant to seek further clarification on any aspect of the study.
Unrepresentative Samples
Researchers at universities across Canada regularly conduct studies using students enrolled in introductory psychology classes as a common pool of available research participants. In many cases, the students receive a small course credit as a direct incentive for their participation so that psychologists and graduate students can obtain the needed participants to further the interests of science, their own research agendas, and important degree requirements. To ensure voluntary participation from an ethical perspective, students who do agree to participate in research must be allowed to withdraw their participation at any time without penalty (i.e., they would still obtain credit or be able to complete a comparable project for course credit). While clearly a convenient sample, a group of psychology majors seeking an arts or science degree is unlikely to represent the broader university population enrolled in any number of other programs, such as commerce, communication studies, or contemporary popular music. Similarly, Canadian residents who volunteer as experimental research participants tend to be different in important ways from the general population. Rosenthal and Rosnow (1975), for example, found that the typical volunteer in experimental research was more intelligent, more sociable, and from a higher social class. More recently, Stahlmann et al. (2024) found that people with agreeable, extraverted and open/intellectual personalities were more likely to engage in volunteerism and other forms of civic engagement.
Unrepresentative samples are especially problematic for claiming the effectiveness of programs for things like drug treatment since the participants who self-select into treatment tend to be the most motivated and most likely to benefit from treatment. Campbell and Stanley (1963) refer to this threat as a selection by treatment interaction effect since those most susceptible to the independent variable have placed themselves in the study. That is not to say that unwilling participants should be coerced into treatment just to balance out the sample. Research ethics aside, research has also shown that court-ordered participants are more resentful and less committed to the objectives of drug treatment programs (Sullivan, 2001).

Test Yourself
- What is experimenter bias and how can this be minimized in an experiment?
- What is participant reactivity and how can this be controlled for in an experiment?
- Why is a volunteer sample unlikely to be representative of the larger population from which it was drawn?
Activity: Threats to Validity
CHAPTER SUMMARY
- Describe the rationale underlying an experimental method.
In an experiment, at least one independent variable is manipulated by a researcher to measure its effects (if any) on a dependent variable. - Identify the criteria needed to establish causality and explain which features of an experiment support the testing of cause–effect relationships.
To establish causality, two variables must be related in a logical way, the presumed cause must precede the effect in time, and the cause should be the most plausible, ruling out rival explanations. Strict control over the environment and random assignment to the experimental and control group helps to ensure that the only difference between the two groups results from the independent variable. - Differentiate between basic and classic experimental designs; explain how exposure to the independent variable differs in between-subjects versus within-subjects designs; and explain why some designs are classified as quasi-experimental.
A basic experimental design includes random assignment, an experiment and control group, the manipulation of an independent variable experienced by the experimental group, and the measurement of a dependent variable. A classic experiment includes these features along with a pre-test measure of the dependent variable prior to the manipulation of the independent variable. In a between-subjects design, participants in the experimental group are exposed to only one level of the independent variable. In a within-subjects design, participants in the experimental group are exposed to all levels of the independent variable. A quasi-experimental design lacks one of the features of a true experiment, such as random assignment or a control group. - Define internal and external validity.
Internal validity is the capacity to demonstrate an experimental effect and to rule out rival explanations for that effect. External validity refers to the generalizability of the effect beyond a given experiment to other people in other settings at other times. - Identify and describe potential threats to internal validity.
This chapter discusses eight threats to validity: (1) selection refers to methods used to obtain groups that can result in differences prior to the experimental manipulation; (2) history refers to changes in the dependent variable attributed to external events occurring between the first and second measurement; (3) maturation refers to changes in dependent measure that result from processes within the research participants; (4) selection by maturation interaction refers to a combined effect of initial differences in the groups and maturation; (5) experimental mortality refers to the course of participant drop-out over time; (6) testing refers to changes in the dependent variables that result from experience gained on the pre-test; (7) instrumentation refers to any changes in the way the dependent variable is measured; and (8) statistical regression refers to differences produced by the tendency for extreme scores to become less extreme. - Identify and describe potential threats to external validity.
This chapter discusses three threats to external validity: (1) experimenter bias exists when researchers influence the behaviour of research participants in a manner that favours the outcomes they anticipate; (2) participant reactivity refers to the tendency for research participants to act differently during a study simply because they are aware that they are participating in a research study; and (3) unrepresentative samples, such as introductory psychology students or other groups that self-select into experiments, are likely different in important ways from the population of interest.
RESEARCH REFLECTIONS
-
- Visit the home page for Psychological Research on the Net. This website, maintained by John H. Krantz, Ph.D., lists ongoing web-based psychology experiments by general topic (e.g., mental health, gender, cyber). Select a recently added study of interest to you and do the following:
- List the name of the study and the affiliated primary researcher(s).
- Describe the purpose of the study as identified in the associated consent form.
- Outline the procedures for potential participants.
- Based on details provided about the study, describe one potential threat to internal or external validity discussed in this chapter that could impact the results of your selected study.
- Go to “Sheldon and Amy’s Date Night Experiment—The Big Bang Theory” on YouTube to watch a short clip from the popular television series. In this clip, Amy sets up an experiment to test whether events associated with fond memories for Sheldon can be directed toward her, so she can accelerate their intimate relationship.
- Does the experimental design used by Amy fit the criteria for a true experimental design? Why or why not?
- Why is it impossible to prove causality in this instance?
- What recommendations would you make to Amy to improve upon her design, so she could be more confident that her manipulation is working?
- Read the following article: Rodríguez Fuentes et al. (2023). University coaching experience and academic performance. Education Sciences, 13(3), 248.
- Why was a quasi-experimental design used in this study?
- What is the main independent variable and how was it manipulated?
- What is the main dependent variable and how was it measured?
- Does coaching improve academic performance? What features of this study increase your confidence in the findings?
- Are there any potential threats to internal or external validity relevant to this study? Explain your response.
- Visit the home page for Psychological Research on the Net. This website, maintained by John H. Krantz, Ph.D., lists ongoing web-based psychology experiments by general topic (e.g., mental health, gender, cyber). Select a recently added study of interest to you and do the following:
LEARNING THROUGH PRACTICE
Objective: To design an experimental taste test
Directions:
- Pair up with someone else in class.
- Discuss whether you believe people can accurately identify their preferred food or beverage brands from among a sample of competitors’ brands.
- Come up two testable hypotheses of interest related to specific taste preferences. For example, H1: Participants will be able to identify their stated cola preference in a blind taste test between Pepsi and Coke.
- Reflecting on threats to internal validity, identify factors that you think might influence taste and how you might control for these in your experimental design.
- Write a detailed procedure section describing how you would design a study to test one of your hypotheses. Provide enough detail so that others could replicate it. See below for some considerations to address in your procedures section:
- What materials will need to carry out this study?
- How will you order the presentation of the beverages or food items?
- What sort of instructions will you give participants?
- How will you measure preference?
RESEARCH RESOURCES
- For students and researchers with statistical proficiency who want to learn more about research designs for special circumstances and about more complex experimental designs, refer to chapters 10 and 11 in Cozby, P. C. et al., (2020). Methods in behavioural research (3rd Canadian ed.). McGraw-Hill Education.
- To learn about independent-groups, dependent-groups, and single-participant designs, see chapters 7 to 9 in Rooney, B. J., and Evans, A. N. (2019). Methods in psychological research (4th ed.). Sage.
- For advice on conducting experimental research online using open-source software, see Peirce, J., Hirst, R., & MacAskill, M. (2022). Building experiments in PsychoPy (2nd ed.). Sage.
- For a critique and re-evaluation of Zimbardo’s Stanford Prison study, check out Michael Stevens’ The Stanford Prison Experiment video (part of Mind Field Season 3 Episode 4) posted to YouTube posted on December 19, 2018.
- Opening quote retrieved from https://www.brainyquote.com/. ↵
A research method in which a researcher manipulates an independent variable to examine its effects on a dependent variable.
The variable that is manipulated in an experiment and is presumed to be the cause of some outcome.
The variable that is measured in an experiment and is the outcome.
A method for assigning cases in which chance alone determines receipt of the experimental manipulation.
The group that experiences the independent variable in an experiment.
The group that does not experience the independent variable in an experiment.
An experimental design that includes random assignment, an experimental and a control group, the manipulation of an independent variable, and a post-test measurement of the dependent variable.
An experimental design that includes random assignment, an experimental and a control group, a pre-test measure of a dependent variable, the manipulation of an independent variable, and a post-test measure of the same dependent variable.
A type of design in which the experimental group is exposed to only one level of the independent variable.
A type of design in which the experimental group is exposed to all possible levels of the independent variable.
Differences in the dependent variable that result from the order in which the independent variable is presented.
An experimental design that lacks one or more of the basic features of a true experiment, including random assignment or a control group.
A quasi-experimental design lacking random assignment in which two groups are compared following a treatment.
A quasi-experimental design lacking a control group, in which one group is examined following a treatment.
The capacity to demonstrate an experimental effect and to rule out rival explanations for that effect.
The generalizability of an experimental effect.
A naturally occurring experiment that takes place in a real-life setting.
Methods used to obtain groups that can result in differences prior to the experimental manipulation.
Changes in the dependent measure attributed to external events outside of the experiment.
Changes in the dependent measure that result from naturally occurring processes within the research participants themselves over the period of treatment.
A combined effect of maturation and initial differences in the groups at the onset of the study.
The course of participant drop-out over time.
Changes in the dependent measure that result from experience gained on the pre-test.
Differences produced by changes in the way the dependent variable is measured.
Differences produced by the tendency for extreme scores to become less extreme.
The tendency for researchers to influence the behaviour of research participants in a manner that favours the outcomes they anticipate.
The tendency for research participants to act differently during a study simply because they are aware that they are participating in a research study.
A threat to external validity produced by the self-selection of participants susceptible to the independent variable.
